whichFlower : a flower species recognition app using tensorflow/keras and React-Native

As a passionate person about computer vision (CV), I came to know that model deployment is also important in model development process because the usefulness of a model is measured by the satisfaction of end users. In a previous project I named DEmoClassi (Demographic (age, gender race) and Emotion (happy, neutral, angry, ...) Classification) I tried to turned my trained models in a standalone python module that can be run on windows/Linux using OpenCV. You can check it here.
In this new project I decided to give mobile technologies a try. Today the models are migrating more and more to the edge devices (mobile, sensors, ... IOT in general). So I started by learning React-Native, a cross-platform mobile development framework developed by Facebook. The course is available on youtube, it is a little bit long, but it worth learning it. The end goal for me was to combine my 2 passions, CV and programming into another project : this time I opted for CV model training and deployment on mobile device of a flower species recognition app I called, with no suspens, `WhichFlower`.
I'll try to describe my journey using this post composed of three sections :
- Exploratory Data Analysis in which I analyse the flower images dataset I'll use
- Image classification models training
- Model deployment using React-Native
<!DOCTYPE html>
Exploratory Data Analysis¶
The dataset I'll explore here comes from kaggle and can be downloaded following this link. It consists of flower images belonging to five flower species :
- Daisy
- Dandelion
- Rose
- Sunflower
- Tulip
First, let's import some useful libs :
%load_ext autoreload
%autoreload 2
import sys
sys.path.append("../utils") # or whatever the path to the utils directory containing the utilities script
from bokeh.io import output_notebook
from data_utils import split_flower_data
from plot_utils import display_sample_images, plot_class_distribution, plot_image_dimensions
output_notebook()
%matplotlib inline
The original dataset is not divided into training, validation and test sets, let's do it :
train_percent = 0.7 # part of the data to consider for train set
root_folder = "../../../flowers-recognition/flowers" # directory containing subdirectory
# each containing images for 1 class
out_folder = "../../../flowers-recognition/split_flower" # folder where to save the split data
classes = ['daisy', 'dandelion', 'rose', 'sunflower', 'tulip'] # class names corresponding also to subdirs on `root_folder`
%%time
split_flower_data(root_folder, out_folder, classes, train_percent)
After data spliting, let's display some sample images for each class from training data :
sample_path = "../../../flowers-recognition/split_flower/train/"
display_sample_images(sample_path)





display_sample_images(sample_path)





display_sample_images(sample_path)





Some images are quite noisy, as they are not only composed of the flower picture, or sometimes the flower is not even visible. We should pay particular attention when assessing the model's performance as it may be affected by these noisy samples.
One important aspect to investigate is the distribution of classes in our dataset, as imbalanced dataset may yield poor results. Following is the distribution of our data in the train, validation and test sets :
path_train = "../../../../COMPUTER_VISION/flowers-recognition/split_flower/train"
path_valid = "../../../../COMPUTER_VISION/flowers-recognition/split_flower/valid"
path_test = "../../../../COMPUTER_VISION/flowers-recognition/split_flower/test"
plot_class_distribution(path_train, title="Train set classes distribution")
plot_class_distribution(path_valid, title="Validation set classes distribution")
plot_class_distribution(path_test, title="Test set classes distribution")
From above plots, we can see that the dataset is fairly balanced. There are two classes -dandelion and tulip- each with a little more than 20% of the data. The other classes have proportions of around 17-18%.
Overall, we have 3028 training samples, 651 validation and 644 test ones.
When using a pretrained model for transfer learning we may be required to resize our images to match the original model input shape. In this case the choice of the images dimensions is direct.
However for our own custom models we may need some insights for choosing the right dimensions. Let's visualize the dimensions -height and width- from the training images :
plot_image_dimensions(path_train)
The mean height is around 245-260 and mean width around 320-350. We may take these values into account when resizing images with custom dimensions.
<!DOCTYPE html>
Flower images classification¶
In this notebook I'll go through training some neural network models in the task of flower image classification (for more information about the dataset see the notebook EDA.ipynb in the same directory)
Let's first clone a repository where I store my utility functions for data processing and model training and evaluation
!git clone https://AlkaSaliss:********@github.com/AlkaSaliss/flowerClassif.git
# # Run this cell to mount your Google Drive.
from google.colab import drive
drive.mount('/content/drive')
Install and import some ncessary packages
# !pip install tensorflow==1.13.1 # uncomment this if using TPU instead of GPU on google colab
!pip install talos scipy==1.2 git+https://www.github.com/keras-team/keras-contrib.git
import sys
sys.path.append('/content/flowerClassif/utils')
import tensorflow as tf
import keras
import keras_contrib
from google.colab import files
import importlib
import os
from data_utils import split_flower_data
from plot_utils import plot_training_history
from model_utils import plot_confusion_matrix
from model_utils import inference_val_gen
from model_utils import CopyCheckpointToDrive
import matplotlib.pyplot as plt
import bokeh
from bokeh.io import output_notebook
from bokeh.resources import INLINE
from bokeh.layouts import gridplot, row
from bokeh.plotting import show, figure
from bokeh.models import ColumnDataSource
import json
import numpy as np
import pandas as pd
import talos as ta
import logging
import tqdm
output_notebook(resources=INLINE)
%matplotlib inline
print(tf.__version__)
print(tf.test.is_gpu_available())
1. Loading data¶
The flower dataset is hosted on kaggle, thus we need to donwload it using the kaggle CLI. (note that to install the kaggle CLI you'll simply do : pip install kaggle)
- Copy kaggle credentials file from google drive, so that we can authenticate with the kaggle CLI :
# create a directory for storing kaggle credentials if it doesn't exist
os.makedirs('/root/.kaggle', exist_ok=True)
# copy the credential file in the reight directory
!cp "/content/drive/My Drive/kaggle.json" /root/.kaggle/kaggle.json
Download the data from kaggle and save it to the data directory :
# create a directory where the data will be stored
os.makedirs('/content/data', exist_ok=True)
!kaggle datasets download -d alxmamaev/flowers-recognition --unzip -p /content/data/
Finally we split the dataset into train (70%), test (15%) and validation (15%) sets :
data_path = '/content/data/flowers/'
out_path = '/content/data/flowers-split'
classes = ['daisy', 'dandelion', 'rose', 'sunflower', 'tulip']
train_split = 0.7
split_flower_data(data_path, out_path, classes, train_split)
2. Train a baseline CNN¶
To ensure everything is ok, let's train a simple CNN model a s a baseline.
First we create data generators for our flower images :
train_path = "/content/data/flowers-split/train/"
valid_path = "/content/data/flowers-split/valid/"
train_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255
)
val_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
)
train_data = train_gen.flow_from_directory(train_path, target_size=(224, 224), batch_size=128)
val_data = val_gen.flow_from_directory(valid_path, target_size=(224, 224), batch_size=256, shuffle=False)
Next let's create the keras model
tf.keras.backend.clear_session()
simple_cnn = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, 5, activation='relu', input_shape=(224, 224, 3),
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.Conv2D(64, 5, activation='relu',
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(128, 5, activation='relu',
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.Conv2D(128, 5, activation='relu',
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dense(128, activation='relu',
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dense(5, activation='softmax')
])
simple_cnn_tpu = tf.contrib.tpu.keras_to_tpu_model(
simple_cnn,
strategy=tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
)
)
simple_cnn_tpu.compile(
optimizer=tf.train.AdagradOptimizer(learning_rate=1e-3),
loss='categorical_crossentropy',
metrics=['accuracy']
)
print(simple_cnn_tpu.summary())
Before starting training let's add some callbacks :
- tensorboard
- early_stopping
- model checkpointing
os.makedirs("/content/data/checkpoints/", exist_ok=True)
logdir = '/content/data/logs/simple_cnn_tpu'
os.makedirs(logdir, exist_ok=True)
tb_callback = tf.keras.callbacks.TensorBoard(log_dir=logdir)
earlystop_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=50, restore_best_weights=True, verbose=1)
ckpt_path = '/content/data/checkpoints/simple_cnn_tpu.h5'
os.makedirs("/content/data/checkpoints/", exist_ok=True)
ckpt_callback = tf.keras.callbacks.ModelCheckpoint(ckpt_path)
list_callbacks = [earlystop_callback, ckpt_callback]
history = simple_cnn_tpu.fit_generator(train_data,
validation_data=val_data,
epochs=300,
callbacks=list_callbacks)
now that the training is end, let's visualize the training and validation metrics :
plot_training_history(history)
Let's download the history data and the model :
history_dict = {k: [float(i) for i in v] for k, v in history.history.items()}
json.dump(history_dict, open('/content/data/checkpoints/simple_cnn_tpu.json', 'w'))
files.download("/content/data/checkpoints/simple_cnn_tpu.json")
files.download("/content/data/checkpoints/simple_cnn_tpu.h5")
Finally let's evaluate the model by ploting some classification metrics and confusion matrix
simple_cnn_tpu.load_weights("/content/data/checkpoints/simple_cnn_tpu.h5")
Get the true labels from generator, and predictions from the model :
y_true = np.concatenate([y for y in inference_val_gen(val_data, gen_type="y")])
y_true.shape
# Make predictions
y_pred = simple_cnn_tpu.predict_generator(inference_val_gen(val_data), steps=len(val_data), verbose=1)
y_pred = np.argmax(y_pred, axis=1)
y_pred.shape
plot the confusion matrix
# get the labels and labels names
label_items = sorted(list(val_data.class_indices.items()), key=lambda x: x[1])
label_names = [item[0] for item in label_items]
labels = [item[1] for item in label_items]
print(labels)
print(label_names)
plot_confusion_matrix(y_true, y_pred, title='Classification Report - CNN baseline',
labels_=labels, target_names=label_names, normalize=False)

We got an accuracy of 77% with this baseline CNN. It seems that the most difficult class to predict by the model is the class rose, which presents the lowest recall value (59%).
Often when the model is wrong about this class (rose), it misclassifies it as a tulip.
3. Baseline + data augmentation¶
Add some data augmentation techniques to see if it helps improve the model performance
train_path = "/content/data/flowers-split/train/"
valid_path = "/content/data/flowers-split/valid/"
train_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
horizontal_flip=True,
vertical_flip=True,
rotation_range=15,
width_shift_range=0.2,
height_shift_range=0.2
)
val_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
)
train_data = train_gen.flow_from_directory(train_path, target_size=(224, 224), batch_size=128)
val_data = val_gen.flow_from_directory(valid_path, target_size=(224, 224), batch_size=256, shuffle=False)
tf.keras.backend.clear_session()
simple_cnn = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, 5, activation='relu', input_shape=(224, 224, 3),
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.Conv2D(64, 5, activation='relu',
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(128, 5, activation='relu',
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.Conv2D(128, 5, activation='relu',
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dense(128, activation='relu',
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dense(5, activation='softmax')
])
simple_cnn_tpu_dataaug = tf.contrib.tpu.keras_to_tpu_model(
simple_cnn,
strategy=tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
)
)
simple_cnn_tpu_dataaug.compile(
optimizer=tf.train.AdamOptimizer(learning_rate=1e-3),
loss='categorical_crossentropy',
metrics=['accuracy']
)
print(simple_cnn_tpu_dataaug.summary())
earlystop_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=50, restore_best_weights=True, verbose=1)
ckpt_path = '/content/data/checkpoints/simple_cnn_tpu_dataaug.h5'
os.makedirs("/content/data/checkpoints/", exist_ok=True)
ckpt_callback = tf.keras.callbacks.ModelCheckpoint(ckpt_path)
list_callbacks = [earlystop_callback, ckpt_callback]
history = simple_cnn_tpu_dataaug.fit_generator(train_data,
validation_data=val_data,
epochs=300,
callbacks=list_callbacks)
plot_training_history(history)
history_dict = {k: [float(i) for i in v] for k, v in history.history.items()}
json.dump(history_dict, open('/content/data/checkpoints/simple_cnn_tpu_dataaug.json', 'w'))
files.download("/content/data/checkpoints/simple_cnn_tpu_dataaug.json")
files.download("/content/data/checkpoints/simple_cnn_tpu_dataaug.h5")
Model evaluation with classification report
# load the best model
simple_cnn_tpu_dataaug.load_weights("/content/data/checkpoints/simple_cnn_tpu_dataaug.h5")
Get the true labels from generator, and predictions from the model :
y_true = np.concatenate([y for y in inference_val_gen(val_data, gen_type="y")])
y_true.shape
y_pred = simple_cnn_tpu_dataaug.predict_generator(inference_val_gen(val_data), steps=len(val_data), verbose=1)
y_pred = np.argmax(y_pred, axis=1)
y_pred.shape
plot the confusion matrix
# get the labels and labels names
label_items = sorted(list(val_data.class_indices.items()), key=lambda x: x[1])
label_names = [item[0] for item in label_items]
labels = [item[1] for item in label_items]
print(labels)
print(label_names)
plot_confusion_matrix(y_true, y_pred, title='Classification Report - CNN baseline',
labels_=labels, target_names=label_names, normalize=False)

Using data augmentation made us gain 4% of accuracy over the baseline model, going from 77% to 81%.
Here also we can see the modst difficult classes to identify by this model are daisy (70% of recall) and rose (73% of recall).
As previously, the model confounds rose with tulip when making mistakes. ==> maybe we need to more weight on this class to help improve its classification.
Hyperparameters search with talos¶
Talos is a hyperparameters tuning library for keras models. You can check it here
We'll tune three hyperparameters :
- kernel size between 3 and 5
- dropout rate : 0.25 or 0.5
- activation function for hidden layers : relu or elu
train_path = "/content/data/flowers-split/train/"
valid_path = "/content/data/flowers-split/valid/"
train_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
horizontal_flip=True,
vertical_flip=True,
rotation_range=15,
width_shift_range=0.2,
height_shift_range=0.2
)
val_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
)
train_data = train_gen.flow_from_directory(train_path, target_size=(224, 224), batch_size=128)
val_data = val_gen.flow_from_directory(valid_path, target_size=(224, 224), batch_size=512, shuffle=False)
Create a directory in google drive where to save the results of hp-search
result_path = "/content/drive/My Drive/DeepLearning/flowers/hp_search_results/run1"
os.makedirs(result_path, exist_ok=True)
First we define a dictionary containing ranges/choices of the hyperparameters we want to optimize :
params = {
"kernel_size": [3, 5],
"dropout": [0.25, 0.50],
"activation": ["relu", "elu"],
}
Then we define a function that takes as input the data and the hyperparametrs dictionary. The talos library expects the data in four parts : training features, training labels, validation features and validation labels. But in our case we are working with generators, so I will just passed dummy x_train, y_train, x_val and y_val to the optimization function; and in the function I'll access the generators I created as global variable to do my training :
def model_fn(x_train, y_train, x_val, y_val, params):
tf.keras.backend.clear_session()
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, params['kernel_size'],
activation=params['activation'],
input_shape=(224, 224, 3),
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.Conv2D(64, params['kernel_size'],
activation=params['activation'],
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.MaxPooling2D(2),
tf.keras.layers.Dropout(params['dropout']),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(128, params['kernel_size'],
activation=params['activation'],
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.Conv2D(128, params['kernel_size'],
activation=params['activation'],
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.GlobalAvgPool2D(),
tf.keras.layers.Dropout(params['dropout']),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dense(64,
activation=params['activation'],
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dense(5, activation='softmax')
])
tpu_model = tf.contrib.tpu.keras_to_tpu_model(
model,
strategy=tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(
tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
)
)
tpu_model.compile(
optimizer=tf.train.AdamOptimizer(learning_rate=1e-3, ),
loss=tf.keras.losses.categorical_crossentropy,
metrics=['acc']
)
out = tpu_model.fit_generator(train_data, validation_data=val_data,
epochs=75)
return out, tpu_model.sync_to_cpu()
x_dum, y_dum = np.zeros((1, 224, 224, 3)), np.zeros((1, 5))
h = ta.Scan(x_dum, y_dum, params, model_fn, experiment_no="1")
# Get the best model index with highest 'val_categorical_accuracy'
model_id = h.data['val_acc'].astype('float').argmax() - 1
# Clear any previous TensorFlow session.
tf.keras.backend.clear_session()
# Load the model parameters from the scanner.
model = tf.keras.models.model_from_json(h.saved_models[model_id])
model.set_weights(h.saved_weights[model_id])
model.summary()
model.save(os.path.join(result_path, 'best_model.h5'))
h.data.to_csv(os.path.join(result_path, 'configs.csv'), index=False)
Load best configuration and train a model using it :
configs = pd.read_csv(os.path.join(result_path, 'configs.csv')).sort_values(['val_acc'])
configs
The best hyperparameters configuration is :
- kernel_size : 5
- activation : relu
- dropout : 0.25
tf.keras.backend.clear_session()
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, 5,
activation='relu',
input_shape=(224, 224, 3),
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.Conv2D(64, 5,
activation='relu',
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.MaxPooling2D(2),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(128, 5,
activation='relu',
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.Conv2D(128, 5,
activation='relu',
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.GlobalAvgPool2D(),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dense(64,
activation='relu',
kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dense(5, activation='softmax')
])
tpu_model = tf.contrib.tpu.keras_to_tpu_model(
model,
strategy=tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(
tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
)
)
tpu_model.compile(
optimizer=tf.train.AdamOptimizer(learning_rate=1e-3, ),
loss=tf.keras.losses.categorical_crossentropy,
metrics=['acc']
)
print(tpu_model.summary())
# define callbacks
earlystop_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=100, restore_best_weights=True, verbose=1)
ckpt_path = '/content/data/checkpoints/best_from_hp_search.h5'
os.makedirs("/content/data/checkpoints/", exist_ok=True)
ckpt_callback = tf.keras.callbacks.ModelCheckpoint(ckpt_path, monitor='val_loss')
# special callback to copy the best model checkpoint from local storage to google drive
dest_path = "/content/drive/My Drive/DeepLearning/flowers/hp_search_results/best"
os.makedirs(dest_path, exist_ok=True)
copy_cb = CopyCheckpointToDrive(ckpt_path, dest_path)
list_callbacks = [earlystop_callback, ckpt_callback, copy_cb]
%%time
history = tpu_model.fit_generator(train_data, validation_data=val_data, callbacks=list_callbacks,
epochs=300)
plot_training_history(history)
Get the true labels from generator, and predictions from the model :
y_true = np.concatenate([y for y in inference_val_gen(val_data, gen_type="y")])
y_true.shape
# Load best model
tpu_model.load_weights("/content/data/checkpoints/best_from_hp_search.h5")
y_pred = tpu_model.predict_generator(inference_val_gen(val_data), steps=len(val_data), verbose=1)
y_pred = np.argmax(y_pred, axis=1)
y_pred.shape
plot the confusion matrix
# get the labels and labels names
label_items = sorted(list(val_data.class_indices.items()), key=lambda x: x[1])
label_names = [item[0] for item in label_items]
labels = [item[1] for item in label_items]
print(labels)
print(label_names)
plot_confusion_matrix(y_true, y_pred, title='Classification Report - CNN baseline',
labels_=labels, target_names=label_names, normalize=False)

Using hyperparameter search led us to 1% gain in accuracy. We are still facing overfitting issue, see accuracy and loss curves above. This could be explained by the fact that we only have about hundred of images per class, which is somehow small to learn a model that'll be capable of generalizing well.
Thus in the next sections we'll go with transfer learning to overcome the small data issue.
Transfer learning¶
Next we'll leverage the power of transfer learning given the small amount of data we have.
VGG16 as features extractor¶
tf.keras.backend.clear_session()
# get the pretrained VGG16 on imagenet
vgg_base = tf.keras.applications.vgg16.VGG16(
include_top=False,
weights='imagenet',
input_shape=(224, 224, 3),
pooling='avg'
)
# freeze pretrained weights
for layer in tqdm.tqdm_notebook(vgg_base.layers):
layer.trainable = False
# add classification layer
vgg_full = tf.keras.Sequential([
vgg_base,
tf.keras.layers.Dense(256, activation='relu', kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.Dense(5, activation='softmax')
])
vgg_full.compile(
optimizer=tf.keras.optimizers.Adam(lr=1e-4),
loss='categorical_crossentropy',
metrics=['acc']
)
print(vgg_full.summary())
# The data generators
train_path = "/content/data/flowers-split/train/"
valid_path = "/content/data/flowers-split/valid/"
train_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
horizontal_flip=True,
vertical_flip=True,
rotation_range=15,
width_shift_range=0.2,
height_shift_range=0.2
)
val_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
)
train_data = train_gen.flow_from_directory(train_path, target_size=(224, 224), batch_size=64)
val_data = val_gen.flow_from_directory(valid_path, target_size=(224, 224), batch_size=64, shuffle=False)
# define callbacks
earlystop_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=50, restore_best_weights=True, verbose=1)
ckpt_path = '/content/data/checkpoints/vgg16_fext.h5'
os.makedirs("/content/data/checkpoints/", exist_ok=True)
ckpt_callback = tf.keras.callbacks.ModelCheckpoint(ckpt_path, monitor='val_loss', verbose=1)
# special callback to copy the best model checkpoint from local storage to google drive
dest_path = "/content/drive/My Drive/DeepLearning/flowers/transfer/vgg/feature_ext"
os.makedirs(dest_path, exist_ok=True)
copy_cb = CopyCheckpointToDrive(ckpt_path, dest_path)
list_callbacks = [earlystop_callback, ckpt_callback, copy_cb]
%%time
# train
history = vgg_full.fit_generator(train_data, validation_data=val_data, callbacks=list_callbacks,
epochs=300)
# plot the learning curves
plot_training_history(history)
Get the true labels from generator, and predictions from the model :
val_data = val_gen.flow_from_directory(valid_path, target_size=(224, 224), batch_size=64, shuffle=False)
y_true = []
len_val_data = len(val_data)
for i, (x, y) in enumerate(tqdm.tqdm_notebook(val_data)):
y_true.append(np.argmax(y, axis=1))
if i == len_val_data - 1:
break
y_true = np.concatenate(y_true)
y_true.shape
# Load best model
vgg_full.load_weights("/content/data/checkpoints/vgg16_fext.h5")
y_pred = vgg_full.predict_generator(val_data, verbose=1)
y_pred = np.argmax(y_pred, axis=1)
y_pred.shape
plot the confusion matrix
# get the labels and labels names
label_items = sorted(list(val_data.class_indices.items()), key=lambda x: x[1])
label_names = [item[0] for item in label_items]
labels = [item[1] for item in label_items]
print(labels)
print(label_names)
plot_confusion_matrix(y_true, y_pred, title='Classification Report - VGG16 features extractor',
labels_=labels, target_names=label_names, normalize=False)

Using VGG16 as features extractor we were able to achieve 83% of accuracy, 1% less than the baseline using the hyperparameters search with talos lib. However with vgg16 the metrics recall and precision, are more balanced between classes.
In the next section we'll unfreeze the VGG convonlutional layers and finetune the whole model.
Finetuning VGG16¶
Here we'll use a lower learning rate to avoid perturbing the already learned information from the pretrained layers
Let's first clone the model from the previous section si we can start finetuning from it
tf.keras.backend.clear_session()
tf.keras.backend.clear_session()
vgg_finetune = tf.keras.models.load_model("/content/data/checkpoints/vgg16_fext.h5")
print(vgg_finetune.summary())
Unfreeze the layers and recompile the model with a lower learning rate
for layer in vgg_finetune.layers:
layer.trainable = True
vgg_finetune.compile(
optimizer=tf.keras.optimizers.Adam(lr=1e-5),
loss='categorical_crossentropy',
metrics=['accuracy']
)
print(vgg_finetune.summary())
# The data generators
train_path = "/content/data/flowers-split/train/"
valid_path = "/content/data/flowers-split/valid/"
train_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
horizontal_flip=True,
vertical_flip=True,
rotation_range=15,
width_shift_range=0.2,
height_shift_range=0.2
)
val_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
)
train_data = train_gen.flow_from_directory(train_path, target_size=(224, 224), batch_size=64)
val_data = val_gen.flow_from_directory(valid_path, target_size=(224, 224), batch_size=64, shuffle=False)
# define callbacks
earlystop_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=100, restore_best_weights=True, verbose=1)
ckpt_path = '/content/data/checkpoints/vgg16_finetune.h5'
os.makedirs("/content/data/checkpoints/", exist_ok=True)
ckpt_callback = tf.keras.callbacks.ModelCheckpoint(ckpt_path, monitor='val_loss', verbose=1)
# special callback to copy the best model checkpoint from local storage to google drive
dest_path = "/content/drive/My Drive/DeepLearning/flowers/transfer/vgg/finetune"
os.makedirs(dest_path, exist_ok=True)
copy_cb = CopyCheckpointToDrive(ckpt_path, dest_path)
list_callbacks = [earlystop_callback, ckpt_callback, copy_cb]
%%time
# train
history_vgg_finetune = vgg_finetune.fit_generator(train_data, validation_data=val_data, callbacks=list_callbacks,
epochs=300)
plot_training_history(history_vgg_finetune)
Evaluation of the finetuned model
val_data = val_gen.flow_from_directory(valid_path, target_size=(224, 224), batch_size=64, shuffle=False)
y_true = []
len_val_data = len(val_data)
for i, (x, y) in enumerate(tqdm.tqdm_notebook(val_data)):
y_true.append(np.argmax(y, axis=1))
if i == len_val_data - 1:
break
y_true = np.concatenate(y_true)
y_true.shape
# Load best model
y_pred = vgg_finetune.predict_generator(val_data, verbose=1)
y_pred = np.argmax(y_pred, axis=1)
y_pred.shape
plot the confusion matrix
# get the labels and labels names
label_items = sorted(list(val_data.class_indices.items()), key=lambda x: x[1])
label_names = [item[0] for item in label_items]
labels = [item[1] for item in label_items]
print(labels)
print(label_names)
plot_confusion_matrix(y_true, y_pred, title='Classification Report - VGG16 Finetuned',
labels_=labels, target_names=label_names, normalize=False)

Finetuning VGG + dropout regularization¶
tf.keras.backend.clear_session()
# get the pretrained VGG16 on imagenet
vgg_base = tf.keras.applications.vgg16.VGG16(
include_top=False,
weights='imagenet',
input_shape=(224, 224, 3),
pooling='avg'
)
print(vgg_base.summary())
# Freeze first layers
set_trainable = False
for layer in vgg_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else :
layer.trainable = False
print(vgg_base.summary())
# add classification layer
vgg_full = tf.keras.Sequential([
vgg_base,
tf.keras.layers.Dropout(0.75),
tf.keras.layers.Dense(256, activation='relu', kernel_initializer=tf.keras.initializers.he_normal()),
tf.keras.layers.Dense(5, activation='softmax')
])
vgg_full.compile(
optimizer=tf.keras.optimizers.Adam(lr=1e-4),
loss='categorical_crossentropy',
metrics=['acc']
)
print(vgg_full.summary())
# The data generators
train_path = "/content/data/flowers-split/train/"
valid_path = "/content/data/flowers-split/valid/"
train_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
horizontal_flip=True,
vertical_flip=True,
rotation_range=15,
width_shift_range=0.2,
height_shift_range=0.2
)
val_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
)
train_data = train_gen.flow_from_directory(train_path, target_size=(224, 224), batch_size=64)
val_data = val_gen.flow_from_directory(valid_path, target_size=(224, 224), batch_size=64, shuffle=False)
# define callbacks
earlystop_callback = tf.keras.callbacks.EarlyStopping(monitor='val_acc', patience=100, restore_best_weights=True, verbose=1)
ckpt_path = '/content/data/checkpoints/vgg16_finetune_dropout.h5'
os.makedirs("/content/data/checkpoints/", exist_ok=True)
ckpt_callback = tf.keras.callbacks.ModelCheckpoint(ckpt_path, monitor='val_acc', save_best_only=True, verbose=1)
# special callback to copy the best model checkpoint from local storage to google drive
dest_path = "/content/drive/My Drive/DeepLearning/flowers/transfer/vgg/finetune"
os.makedirs(dest_path, exist_ok=True)
copy_cb = CopyCheckpointToDrive(ckpt_path, dest_path)
list_callbacks = [earlystop_callback, ckpt_callback, copy_cb]
%%time
# train
history_vgg_finetune = vgg_full.fit_generator(train_data,
validation_data=val_data,
callbacks=list_callbacks,
epochs=300)
plot_training_history(history_vgg_finetune)
Evaluation of the finetuned model
val_data = val_gen.flow_from_directory(valid_path, target_size=(224, 224), batch_size=64, shuffle=False)
y_true = []
len_val_data = len(val_data)
for i, (x, y) in enumerate(tqdm.tqdm_notebook(val_data)):
y_true.append(np.argmax(y, axis=1))
if i == len_val_data - 1:
break
y_true = np.concatenate(y_true)
y_true.shape
y_pred = vgg_full.predict_generator(val_data, verbose=1)
y_pred = np.argmax(y_pred, axis=1)
y_pred.shape
plot the confusion matrix
# get the labels and labels names
label_items = sorted(list(val_data.class_indices.items()), key=lambda x: x[1])
label_names = [item[0] for item in label_items]
labels = [item[1] for item in label_items]
print(labels)
print(label_names)
plot_confusion_matrix(y_true, y_pred, title='Classification Report - VGG16 Finetuned',
labels_=labels, target_names=label_names, normalize=False)

Final evaluation on test set¶
Finally, let's evaluate all the trained models on the held test to choose the best model.
- Baseline CNN
# Loading the test data
test_path = '/content/data/flowers-split/test/'
test_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
)
test_data = test_gen.flow_from_directory(test_path, target_size=(224, 224), batch_size=128, shuffle=False)
# get the true labels
y_true = np.concatenate([y for y in inference_val_gen(test_data, gen_type="y")])
y_true.shape
# Load the best model
model_path = '/content/data/checkpoints/simple_cnn_tpu.h5'
baseline_cnn = tf.keras.models.load_model(model_path)
baseline_cnn.summary()
# Make prediction using baseline model
y_pred = baseline_cnn.predict_generator(inference_val_gen(test_data), steps=len(test_data), verbose=1)
y_pred = np.argmax(y_pred, axis=1)
y_pred.shape
plot the confusion matrix
# get the labels and labels names
label_items = sorted(list(test_data.class_indices.items()), key=lambda x: x[1])
label_names = [item[0] for item in label_items]
labels = [item[1] for item in label_items]
print(labels)
print(label_names)
plot_confusion_matrix(y_true, y_pred, title='Classification Report - CNN baseline',
labels_=labels, target_names=label_names, normalize=False)

- Baseline CNN + Data augmentation
# Load the best model
model_path = '/content/data/checkpoints/simple_cnn_tpu_dataaug.h5'
baseline_cnn_dataaug = tf.keras.models.load_model(model_path)
baseline_cnn_dataaug.summary()
# Make prediction using baseline model
y_pred = baseline_cnn_dataaug.predict_generator(inference_val_gen(test_data), steps=len(test_data), verbose=1)
y_pred = np.argmax(y_pred, axis=1)
y_pred.shape
plot the confusion matrix
plot_confusion_matrix(y_true, y_pred, title='Classification Report - CNN baseline',
labels_=labels, target_names=label_names, normalize=False)

- Tuned hyperparameters with Talos lib
# Load the best model
model_path = "/content/drive/My Drive/DeepLearning/flowers/hp_search_results/best/best_from_hp_search.h5"
best_from_hp_search = tf.keras.models.load_model(model_path)
best_from_hp_search.summary()
# Make prediction using baseline model
y_pred = best_from_hp_search.predict_generator(inference_val_gen(test_data), steps=len(test_data), verbose=1)
y_pred = np.argmax(y_pred, axis=1)
y_pred.shape
plot the confusion matrix
plot_confusion_matrix(y_true, y_pred, title='Classification Report - CNN baseline',
labels_=labels, target_names=label_names, normalize=False)

- VGG as features extractor
# Load the best model
model_path = "/content/drive/My Drive/DeepLearning/flowers/transfer/vgg/feature_ext/vgg16_fext.h5"
vgg16_fext = tf.keras.models.load_model(model_path)
vgg16_fext.summary()
# Make prediction using baseline model
y_pred = vgg16_fext.predict_generator(inference_val_gen(test_data), steps=len(test_data), verbose=1)
y_pred = np.argmax(y_pred, axis=1)
y_pred.shape
plot the confusion matrix
plot_confusion_matrix(y_true, y_pred, title='Classification Report - CNN baseline',
labels_=labels, target_names=label_names, normalize=False)

- Finetuning VGG
# Load the best model
model_path = "/content/drive/My Drive/DeepLearning/flowers/transfer/vgg/finetune/vgg16_finetune.h5"
vgg16_finetune = tf.keras.models.load_model(model_path)
vgg16_finetune.summary()
# Make prediction using baseline model
y_pred = vgg16_finetune.predict_generator(inference_val_gen(test_data), steps=len(test_data), verbose=1)
y_pred = np.argmax(y_pred, axis=1)
y_pred.shape
plot the confusion matrix
plot_confusion_matrix(y_true, y_pred, title='Classification Report - CNN baseline',
labels_=labels, target_names=label_names, normalize=False)

- Finetuning VGG + Dropout
# Load the best model
model_path = "/content/drive/My Drive/DeepLearning/flowers/transfer/vgg/finetune/vgg16_finetune_dropout.h5"
vgg16_finetune_dropout = tf.keras.models.load_model(model_path)
vgg16_finetune_dropout.summary()
# Make prediction using baseline model
y_pred = vgg16_finetune_dropout.predict_generator(inference_val_gen(test_data), steps=len(test_data), verbose=1)
y_pred = np.argmax(y_pred, axis=1)
y_pred.shape
plot the confusion matrix
plot_confusion_matrix(y_true, y_pred, title='Classification Report - CNN baseline',
labels_=labels, target_names=label_names, normalize=False)

Summary¶
Let's summarize all the results in a table to facilitate the comparison:
| Model | Validation accuracy | Test accuracy |
|---|---|---|
| Baseline | 77.29 | 75.46 |
| Baseline+Data augmentation | 81.40 | 80.25 |
| Tuned Hyperparams | 84.45 | 81.79 |
| VGG16 feature extraction | 83.10 | 82.87 |
| VGG16 Finetuned | 88.94 | 86.27 |
| VGG16 Finetuned + dropout | 90.94 | 88.73 |
From the above table we can conclude that the best model in terms of vaidation and test accuracy is the finetuned VGG16 regularized with dropout.
Improvement ideas:
- Tune the hyperparameters for the VGG16 as there may be room for improvements (batch size, dropout rate, learning rate, ...)
- Try different architectures for transfer learning such as Resnet, Xception, ...
- Try to add more data
- Used some advanced techniques such as learning rate scheduling, label smoothing, ...
- Put yours here ...
App structure
The application content walkthrough is beyond the scope of this post. Nevertheless, I'll give an overview of the app in this last section.
The model is deployed using a library called "tflite-react-native" (see this github page for more details. The workflow consists of first converting the trained keras models into tensorflow lite format and use the tflite-react-native library to integrate the tf-lite model into the react-native application.
The application consists mainly of 4 screens for which the code is located in the `screens` folder in the repository. The screens are as follow :
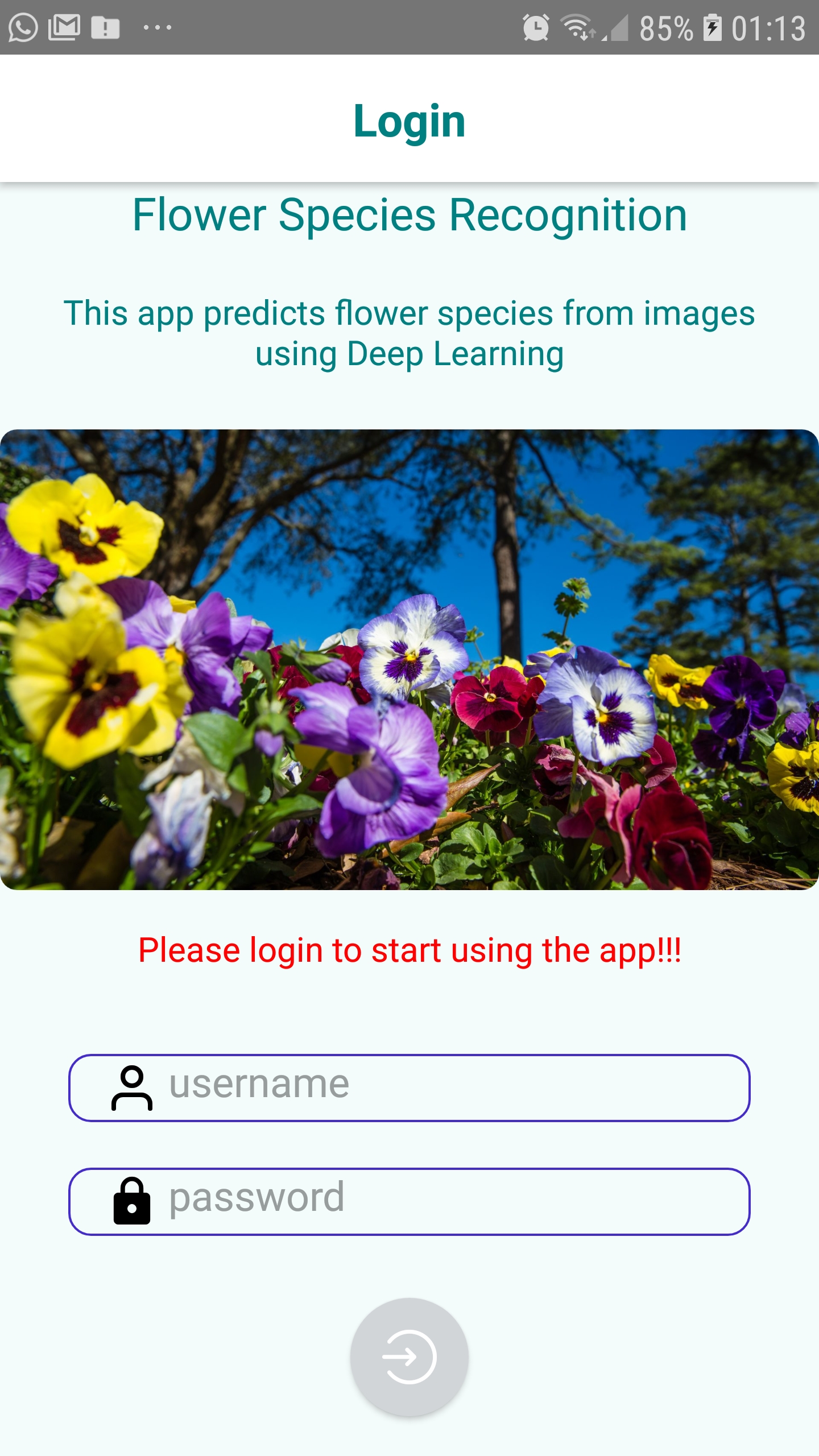
- login screen (`login-screen.js` file) which is the entry point of the app. It contains a simple login form (user name and password). However there is no real control of the user name and passwod being typed as the app is not connected to any server. The eonly control I implemented is the number of character being typed. So it is just a kind of dummy login screen
- Once the user is logged in, he is redirected ot the home screen (`home.js` file) where the user has the possibility to take the picture of a flower using the phone's camera, or upload a flower image directly from his phone's storage
- The camera screen (`camera-screen.js` file) allows the user to capture an image (hopefully a flower one :) ) using the phone's camera
- The image being uploaded/captured, the user passes to the final screen whic allows the user to predict the specie of the corresponding flower image. And that is the predict screen (`predict-screen.js` file)
- There is another file (barChart.js) which contains the implementation code for the bar chart (representing the probability predcited for each flower class) displayed in the predict screen